

Banyak drama Korea yang memberikan informasi yang akurat tentang berbagai subjek. Karena bidang saya adalah security dan programming, saya hanya membahas topik yang berhubungan dengan ilmu saya.
Secara umum, penjelasan berbagai hal yang berhubungan dengan AI sudah cukup akurat, berbagai aktivitas programming yang dilakukan juga menunjukkan hal-hal yang berhubungan dengan AI, walau kadang yang dilakukan/ditunjukkan kepada penonton kurang pas dengan tujuan programnya.
Saya pernah membahas mengenai Hacking di serial Phantom, dan kali ini akan membahas topik Artificial Intelligence atau AI di serial drakor “Start Up” khususnya episode ke-5. Saya hanya akan membahas topik machine learningnya saja, bukan kisah dramanya.
Untuk membaca review awal dramanya bisa dibaca di sini, dan untuk topik bisnis dan investasi yang juga dibahas di drama ini bisa dibaca di sini.
Daftar Isi
Hackathon
Episode ini berfokus pada acara hackathon. Ada banyak format acara hackathon, tapi intinya adalah event singkat (mulai beberapa jam sampai beberapa hari) untuk membuat satu software tertentu yang bisa berfungsi, dan biasanya dipresentasikan di akhir acara. Tidak semua hackathon bertujuan komersial (ada yang untuk amal, untuk bersenang-senang atau sekedar pertemuan regional untuk mencari koneksi).
Di cerita ini, hackathon bertujuan untuk membuat startup baru dengan pitching dari perwakilan teamnya. Dari hasil beberapa hackathon memang sudah ada yang menjadi beberapa startup sukses, sehingga cukup masuk akal menggunakan hackathon untuk menyaring pendanaan startup.
Startup machine learning
Saat ini di berbagai belahan bumi (termasuk juga Indonesia), topik Machine Learning ini masih merupakan topik yang hot. Seingat saya tidak disebutkan di hackathon di cerita ini apakah harus memakai machine learning, tapi sepertinya semua mengarah ke sana. Jadi machine learning ini yang akan jadi fokus posting ini.
Segala macam hal bisa ditambahi dengan machine learning agar lebih menarik. Sebenarnya kadang hanya masalah tren saja, dan kadang penggunaan machine learning kurang tepat atau tidak terlalu membantu. Tidak hanya di bidang IT, banyak bidang lain yang memakai tren tertentu berlebihan.
Contohnya di bidang lain: alpukat sudah ada sejak dulu, tapi baru sekitar 2010 tiba-tiba menjadi sangat populer. Semua makanan diberi alpukat, sampai-sampai demandnya menjadi sangat tinggi dan Mafia di Meksiko pun turun tangan masuk ke bisnis alpukat ini.
Analogi machine learning
Sesuai namanya: artificial intelligence (AI/kecerdasan buatan) adalah kecerdasan yang ditunjukkan oleh mesin buatan manusia. Ada banyak cara untuk membuat AI, dan saat ini yang populer adalah dengan Machine Learning.

Di dalam drama ini sang tokoh pria Nam Do-san membuat analogi machine learning dengan kisah Tarzan dan Jane. Tarzan yang belum pernah bertemu wanita belajar bahwa jika Jane diberi batu Jane tidak suka, jika diberi bunga Jane akan suka, jika Tarzan bersikap memberikan ular Jane tidak suka dan ketika Tarzan memberi kelinci, Jane suka.
Jadi intinya adalah: dengan machine learning, komputer belajar dari data, bukan dengan programmer yang memberi tahu komputer setiap langkah yang harus dilakukan.
Artificial Neural Network
Diceritakan juga bahwa Do-san menyukai merancang Artificial Neural Network (ANN atau Jaringan Syaraf Tiruan). ANN ini merupakan salah satu kelas algoritma machine learning yang paling populer saat ini (machine learning tidak harus memakai ANN).
ANN diilhami dari cara kerja neuron di otak manusia. Pada otak manusia, milyaran neuron terhubung dalam jaringan kompleks, dan tiap neuron hanya melakukan perhitungan kecil, lalu mengirimkan signal ke neuron lain dalam kondisi tertentu.

Saat ini AI yang ada di pasaran masih masuk di level ANI (Artificial Narrow Intelligence), bentuk AI yang hanya bisa untuk tujuan tertentu. Misalnya: AI untuk mengenali foto wajah manusia tidak bisa dipakai untuk mengenali wajah anime. Bahkan kadang AI yang dilatih dengan wajah Asia akan memiliki akurasi rendah jika dicobakan ke ras lain.
Tidak seperti otak manusia yang punya milyaran neuron dan bisa belajar apa saja, jaringan syaraf tiruan jumlah neuronnya sangat sedikit dibandingkan jumlah neuron di otak manusia. Impian para researcher AI adalah AGI (Artificial General Intelligence) yang bisa belajar apa saja seperti manusia, dan bahkan ASI (Artificial Super Intelligence) yang bisa lebih dari kecerdasan manusia.
Saya akan menjelaskan sedikit tentang teknis ANN supaya bisa memberi komentar pada istilah-istilah yang mereka ungkapkan dalam drama ini. Neuron dalam ANN dibagi menjadi beberapa lapisan/layer: input, hidden, dan output.
Lapisan input akan menerima data (seperti indra pada manusia), lapisan output yang mengeluarkan data (di manusia misalnya bentuk outputnya adalah kata-kata), sementara hidden merupakan layer yang memproses data (bagian “otak”).
Ide ANN ini sudah ada sejak lama (1950an), tapi menjadi populer lagi setelah komputer menjadi sangat cepat, dan jumlah hidden layer bisa diperbanyak. Ketika jumlah layer banyak, maka ini disebut deep learning.
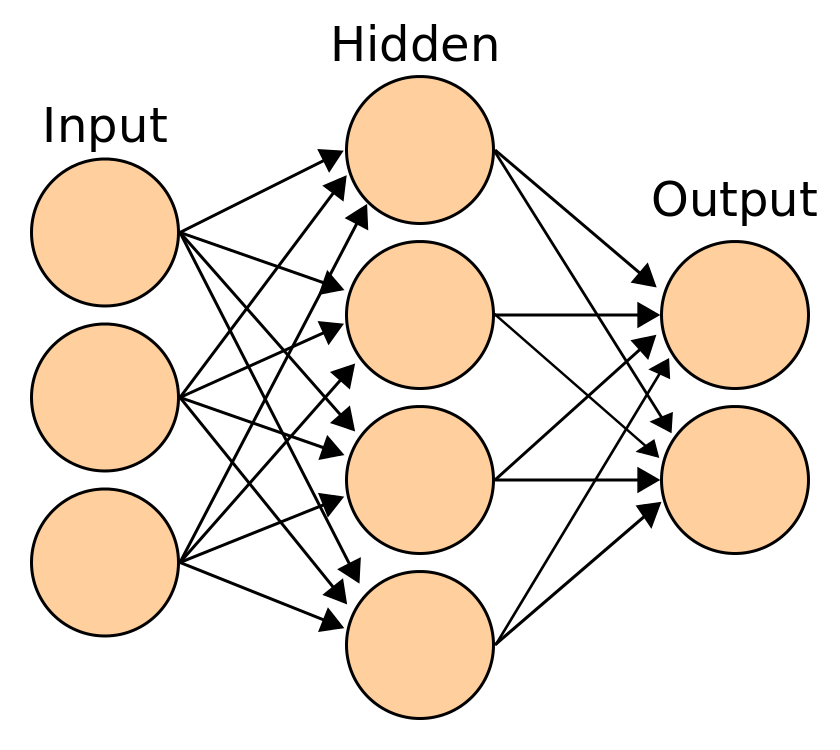
Ketika membuat sistem AI dengan deep learning, kita perlu menentukan input layer yang berhubungan dengan data di dunia nyata. Misalnya ada AI yang memprediksi harga rumah, mungkin inputnya adalah: luas bangunan, luas tanah, lokasi, dsb (bisa ada ratusan). Untuk AI yang berhubungan dengan pemrosesan citra, inputnya biasanya adalah semua titik gambar (piksel, jumlahnya bisa sangat banyak). Outputnya tentunya sesuai dengan yang diinginkan, dalam kasus prediksi harga rumah adalah: harga rumah, dalam kasus pengenalan citra outputnya adalah objek yang dikenali.
Dataset
Untuk mengajari komputer, dibutuhkan contoh data. Pelajaran pertama dalam machine learning biasanya adalah membuat ANN untuk mengenali tulisan tangan angka 0 sampai 9 menggunakan dataset MNIST. Di episode ke-5 ini, diceritakan bahwa panitia hackathon menyediakan banyak dataset, dan salah satunya yang dipakai adalah dataset tulisan tangan dari Bank.
Tim pertama (Samsan Tech) memakai dataset ini untuk menentukan apakah tulisan tangan asli atau palsu. Dalam kasus ini kita butuh input contoh tulisan tangan palsu dan asli. Tidak diceritakan detail berbagai teknik pemalsuan yang berusaha dikenali, apakah misalnya: pemalsuan dengan tulisan manual, pemalsuan dengan cara digital. Mereka harus membuat dataset tulisan tangan palsu sendiri, kecuali jika memang sudah disediakan panitia (bagian ini tidak diceritakan detail).

Salah satu bagian sulit adalah merancang berbagai layer pada ANN. Contohnya harus ditentukan: berapa hidden layer yang dinginkan, berapa neuron di layer pertama, kedua dst. Untuk pemrosesan citra, ada jaringan khusus yang biasanya dipakai yang dikenal dengan nama CNN (Convolutional Neural Network).
Seperti saya singgung sebelumnya: tiap neuron dalam satu layer hanya melakukan perhitungan sederhana, dan dalam kondisi tertentu akan mengirimkan signal ke neuron lain.
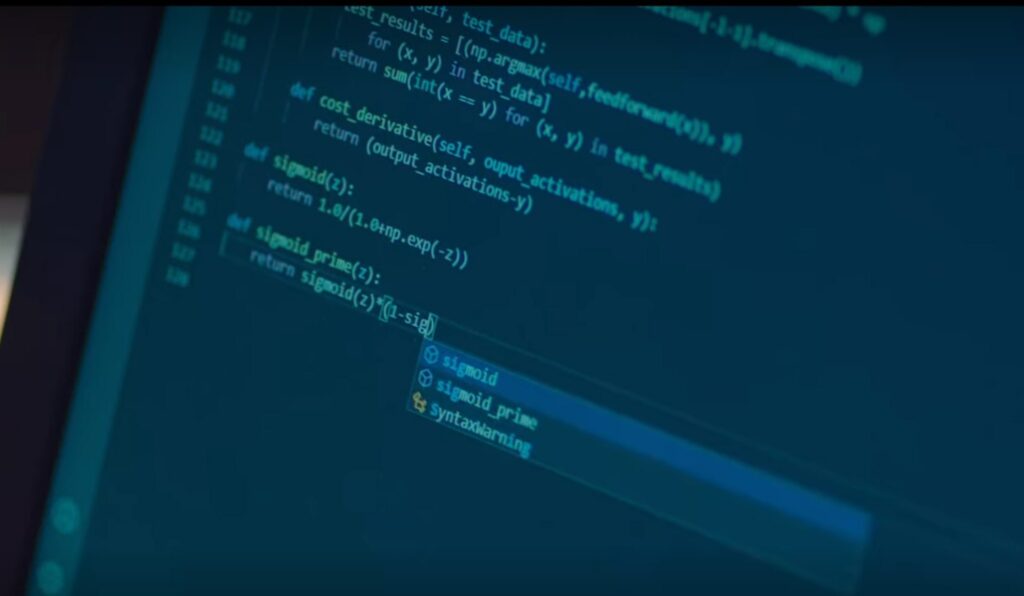
Dalam neuron buatan, keputusan apakah mengirimkan signal atau tidak dilakukan oleh “activation function“. Contoh nama activation function adalah: sigmoid. Nama fungsi ini bisa dilihat di layar programmernya. Seharusnya dalam dunia nyata, untuk acara seperti ini, kita tidak akan sempat mengimplementasikan ini dari awal, cukup memakai library program yang sudah ada.

Proses awal adalah menentukan kira-kira arsitektur networknya seperti apa. Setelah itu hyperparameter perlu ditentukan. Hyperparameter ini adalah parameter/nilai yang diberikan oleh programmer yang tidak dipelajari sendiri oleh komputer, misalnya: berapa jumlah neuron di tiap layer dan fungsi aktivasi apa yang akan dipakai.
Implementasi
Setelah memiliki ide dari dataset yang diberikan, langkah berikutnya adalah mengimplementasikan algoritma tersebut dalam bentuk program. Meskipun nantinya komputer akan belajar sendiri dari data, tapi ada proses-proses yang masih perlu diprogram: membaca data input, mendeskripsikan seperti apa jaringan syaraf tiruannya, membuat tampilan grafis yang manis, menghubungkan ke sistem lain, dsb.
Dari layar yang ditampilkan sepertinya mereka ingin mengimplementasikan Neural Network dari awal tapi kemudian memakai library lain. Ini agak kurang masuk akal, seharusnya mereka memakai library yang lebih high level (misalnya TensorFlow).
Ibaratnya jika ada acara memasak tempe mendoan, tapi di situ terlihat ada kedelai dan raginya. Dalam kasus ini: masuk akal jika ditunjukkan ada kedelai dan ragi untuk membuat tempe, tapi tidak masuk akal jika acara memasak tersebut terbatas waktunya, tapi harus membuat tempe dari kedelai. Lebih aneh lagi karena di akhir mereka memakai library lain, seperti tiba-tiba mengeluarkan tempe yang sudah dibungkus plastik dari Supermarket setelah di awal berusaha membuat tempe dari kedelai dan ragi.
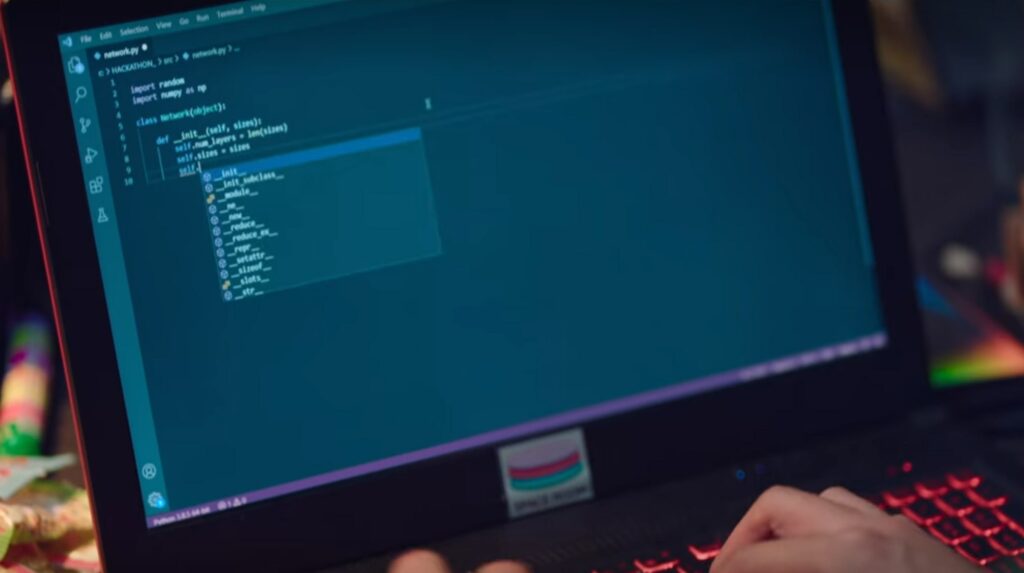
Hal yang kurang konsisten lain adalah: satu anggota tim memakai bahasa pemrograman JavaScript sedangkan yang lain memakai Python. Andaikan melukis bersama, yang satu memakai cat air dan yang satu memakai cat minyak. Bisa sih disambungkan, tapi kurang masuk akal. Dalam kasus ini Javascriptnya bukan dipakai untuk membuat user interface, tapi untuk membuat ANN.
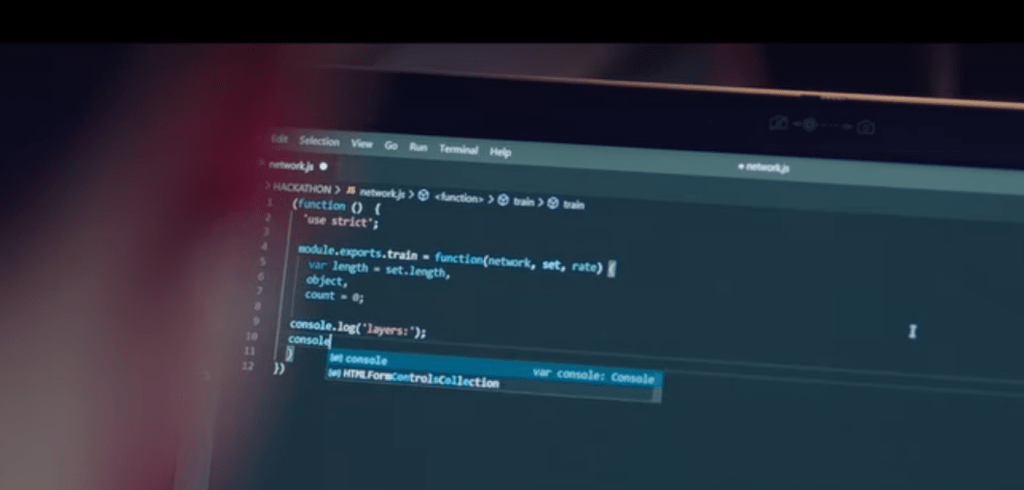
Tapi secara umum, kode-kode yang ditampilkan semuanya masih berhubungan dengan AI. Jadi jika ini adalah acara memasak kue, bahan-bahan dan langkah-langkah yang dilakukan memang masuk akal, tidak tiba-tiba ada bagian menggoreng ayam ditengah-tengah memasak kue.
Training
Jika sudah menentukan arsitektur neural networknya seperti apa, hal yang dilakukan berikutnya adalah training, alias proses di mana komputer belajar. Proses ini bisa memakan waktu lama, model yang kompleks dengan dataset besar bisa memakai waktu berhari-hari sampai berbulan-bulan.
Di awal hackathon diumumkan juga bahwa panitia menyediakan GPU (graphics processing unit) untuk mempercepat proses pelatihan. Awalnya GPU ini hanya untuk mempercepat rendering grafik, tapi fungsi yang disediakan untuk pemrosesan grafik ternyata bisa digunakan untuk mempercepat komputasi ANN hingga ratusan kali lebih cepat dari CPU.

Selain GPU, disebutkan juga panitia menyediakan berbagai API (Application Programming Interface), tapi tidak dijelaskan tepatnya apa. API ini semacam fungsi-fungsi yang bisa diakses (misalnya ada hackathon dari berbagai bank di Indonesia yang melibatkan API mereka). Dalam konteks ide yang mereka kembangkan, sepertinya juga tidak ada API khusus yang dipakai.
Masalah dalam implementasi AI
Diceritakan bahwa di awal mereka kesulitan karena error ratenya masih sangat tinggi. Ada sesuatu yang agak aneh di sini: software yang ditampilkan di latar belakang ternyata adalah Cobalt Strike. Ini adalah software network security, bukan untuk machine learning. Tapi di atas software ini ditempelkan grafik pembelajaran mesin.
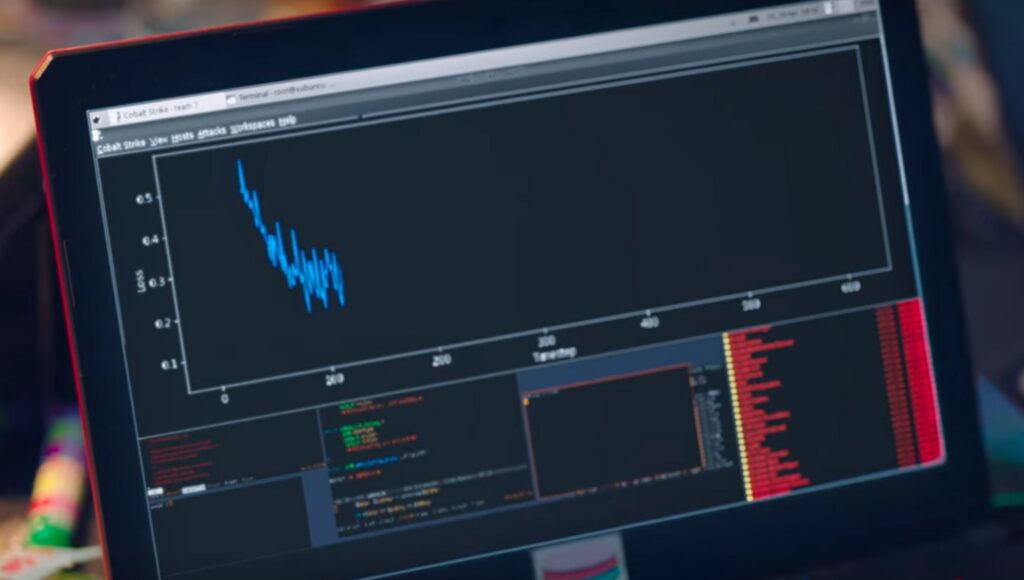
Sementara di sisi lawan (In-jae), meskipun grafik depannya menggunakan grafik training (dengan epoch dan loss di sumbu grafik yang benar), tapi software yang di latar belakangnya adalah debugger (kemungkinan x86dbg atau ollydbg).

Setelah gagal mendapatkan akurasi tinggi, mereka mencoba men-tweak hyperparameter, dan ketika gagal, mereka ingin mengganti fungsi aktivasinya (secara teknis, fungsi aktivasi ini sebenarnya merupakan bagian dari hyperparameter).

Di akhir, mereka mengubah struktur networknya setelah tuning hyperparameter juga mentok.

Adversarial Machine Learning
Dalam cerita ini, tim pesaing memakai AI untuk membuat font tulisan tangan berdasarkan contoh dengan hanya memakai 256 karakter. Font 256 karakter yang dimaksud sepertinya adalah yang ada dalam blok unicode Hangul Jamo. Diceritakan kemudian hasilnya dicobakan apakah dapat dideteksi sebagai palsu oleh model yang dibuat tim pertama. Model yang dibuat tim pertama gagal menentukan bahwa ini adalah tulisan palsu.
Membuat tulisan tangan dengan font biasa sudah bisa dilakukan dari dulu, tapi masalahnya adalah: semua karakter yang sama terlihat sama di posisi manapun. Diceritakan bahwa untuk membuat font yang bagus dibutuhkan waktu bertahun-tahun, ini memang benar, misalnya font Liza butuh waktu 5 tahun.
Sudah banyak juga yang membuat model untuk menghasilkan tulisan tangan berdasarkan teks, tapi hasil pencarian singkat saya saat ini menujukkan belum ada yang menggunakan machine learning untuk membuat font yang memiliki karakter yang random. Jadi ide ini bisa jadi ide startup beneran walau saya tidak tahu apakah banyak yang akan memakai karena banyak font gratis yang bebas lisensi sudah tersedia di internet.
Kemungkinan besar AI untuk membuat font ini menggunakan Generative Adversarial Network (GAN). Contoh aplikasi GAN ini adalah style-transfer, yaitu mengubah foto menjadi mirip lukisan pelukis tertentu. Secara sederhana GAN, kita memiliki dua ANN, yang pertama diajari untuk mengenali sesuatu, misalnya: “ini lukisan Picasso”.
Network ini relatif mudah, berikan saja semua lukisan Picasso dan pelukis lain. Sementara network yang lain diajari supaya menghasilkan sesuatu yang mirip Picasso. Bagian ini lebih sulit: bagaimana supaya tahu menghasilkan lukisan dengan gaya Picasso?
Caranya adalah: output dari network yang menghasilkan gambar diberikan ke network yang mengenali gambar. Jika dinilai bahwa belum mirip Picasso, maka network tersebut akan belajar untuk menghasilkan gambar lain sampai mirip. Dalam kasus ini kita sengaja mempertemukan dua network, supaya network yang satu belajar “membohongi” network lain sampai network lain mengatakan “ini lukisan gaya Picasso”.
Dalam kasus lain, ada yang namanya Adversarial machine learning, yang tujuannya memang untuk mengeksploitasi security neural network lain. Misalnya: kita ingin membuat sistem agar pengenalan wajah akan salah mengenali kita. Dalam kasus ini, tim pesaing yang menghasilkan font ini tidak secara sengaja megimplementasikan Adversarial Machine Learning, tapi ternyata sudah cukup membohongi model yang dibuat tim pertama.

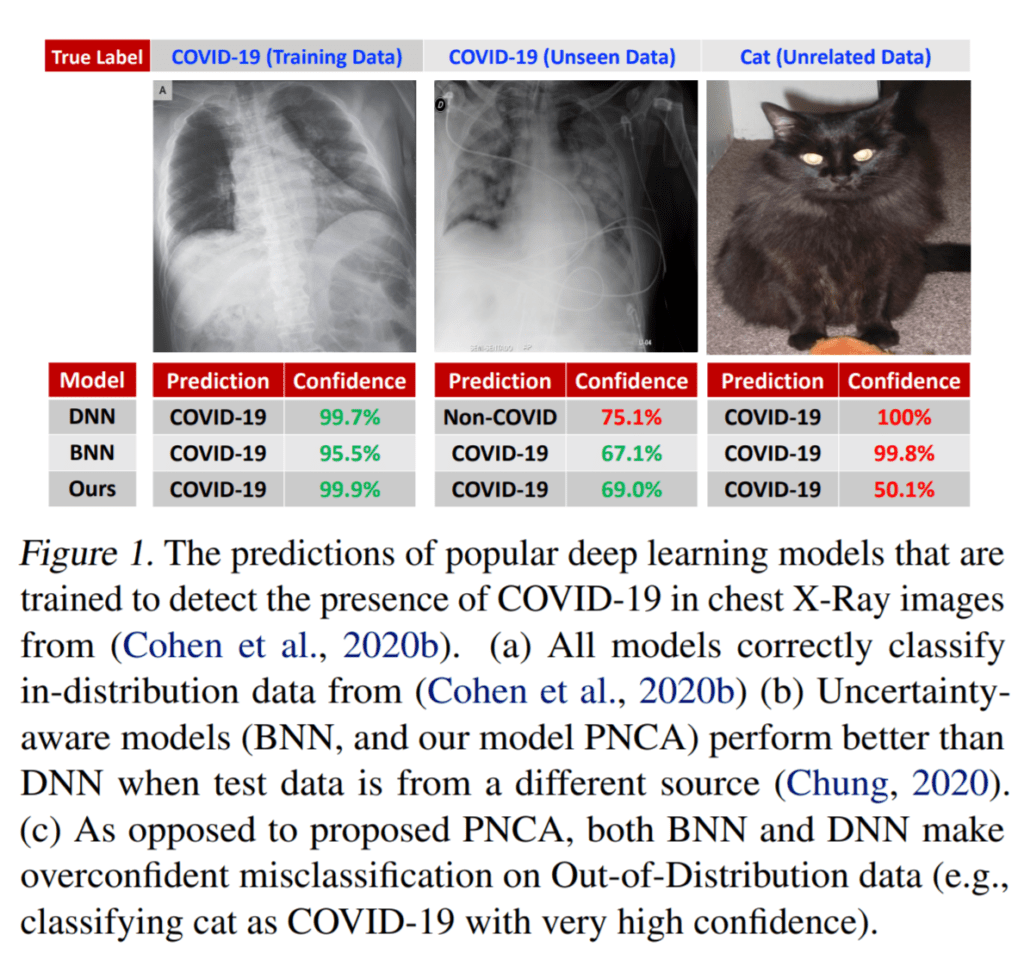
Untuk acara sesingkat hackathon, tidak bisa diharapkan hasilnya sangat bagus. Bisa saja demi terlihat bagus, mereka bisa melakukan “overfitting“, atau mudahnya: kalau diberikan data seperti pada contoh, hasilnya sangat bagus, tapi di luar itu hasilnya tidak bagus. Ini sebenarnya merupakan masalah umum dalam AI, contohnya dalam paper “Can Your AI Differentiate Cats from Covid-19?” ditunjukkan bahwa AI yang klaimnya bisa mendeteksi COVID-19 dengan akurasi tinggi ternyata akan mendeteksi gambar kucing sebagai “Positif Covid”
Penutup
Karena saya tidak mengikuti jalinan ceritanya, saya cukup menikmati bagian teknisnya. Dan walaupun saya menonton di titik tengah, saya juga merasa ceritanya terasa dekat dengan kehidupan saya. Teringat dulu setelah pernikahan, kami harus kembali segera ke bandung untuk jadi panitia di acara Hackhaton di ITB, dan diteruskan dengan presentasi hasil hackathon di Bali dan diikuti dengan bulan madu kami.

Ketika tim yang berusaha mengenali plat nomor gagal, saya tersenyum karena beberapa tahun lalu pernah mengimplementasikan hal serupa untuk plat nomor indonesia.
Saya berharap suatu saat banyak film Indonesia yang juga bisa menjelaskan topik teknologi dalam format menarik seperti ini. Jadi selain menikmati kisahnya, kita juga bisa belajar hal baru. Buat yang jadi tertarik dengan Machine learning ingin belajar lebih banyak mengenai machine learning, ada kursus gratis di Coursera, review coursenya sudah pernah saya tuliskan.
Penulis: Yohanes Nugroho, programmer tinggal di Chiang Mai, tulisan lainnya bisa dibaca di blog.compactbyte.com dan tinyhack.com
Seorang programmer yang tinggal di Chiang Mai.





